Survey of repository preservation policy and activity
Steve Hitchcock, Tim Brody, Jessie M.N. Hey and Leslie
Carr
Preserv Project, IAM Group, School
of Electronics and Computer Science,
University of Southampton, SO17 1BJ, UK
Email:
sh94r@ecs.soton.ac.uk
Preserv is a JISC-funded project within the
programme
Supporting Digital Preservation and Asset Management in Institutions.
Find out more about Preserv.
Version information: This is a DRAFT paper, 9 January 2007, updated
21 February 2007
Abstract
Growth in the number of digital and institutional repositories, and
corresponding growth in the volume of content, means that preparing for
preservation begins to assume a higher priority. So how prepared are
repositories for preservation? The survey put a series of objective,
practical questions to selected repositories among the largest content
providers identified by the Registry of Open Access Repositories
(ROAR), and which were amenable to format profiling using the
PRONOM-DROID
service from the National Archives of the UK. The
aim of the survey is to
inform the investigation of preservation services for repositories,
which we believe will be provided by specialist service providers, and
the profiles provide a benchmark against which to assess the
preliminary requirements of these repositories for preservation.
Preservation service providers need to know the scale and shape of the
task facing
them, and
this survey will enable them to understand repositories and help to
construct appropriate services. The results were revealing:
- No repositories surveyed had a formal preservation policy
- Preservation policy is being preceded by de facto policies on file
formats and transformations without provision for acquiring source
versions
The first finding is not surprising and can be rectified by good
repository policy (not just preservation policy, which will emerge from
general considerations). The second
finding ought to be surprising. Restricting file
formats that can be deposited
unwittingly introduces an additional risk factor, because it typically
leads to original source data being transformed without documentation,
often
prior to deposit in the repository. In other words, documents and
information necessary to the ongoing process of preservation are being
lost and will continue to be so unless
restrictions on presentation formats are accompanied by a requirement
for
the source version to be deposited.
Introduction
Since 2002 institutional repositories (IRs) have seen growth accelerate
both in the number of repositories and in the volume of content
(Hitchcock et al. 2007a):
between 2005 and 2006 this growth was shown to be 25% (repository
numbers) and almost 60% (content). It also brings increasing diversity
in terms of the types of documents deposited in IRs and in terms of the
file formats used. With this growth and diversity comes responsibility
to manage the content effectively. According to Lynch (2003) IRs
represent "an organizational commitment to the stewardship of these
digital
materials, including long-term preservation where appropriate, as well
as organization and access or distribution."
What are repositories, particularly IRs,
doing
about preservation? There is no shortage of advocacy for digital
preservation, and some good general advice on how to construct a
preservation strategy (Kenney et al.
2003), but the suspicion is that little is being done
yet by repositories in practical terms. This survey aimed to find out
through a series of objective, practical questions rather than
leading subjective and hypothetical scenarios. Thus the emphasis is on
what repositories do, and the implications for preservation, rather
than on what they may plan to do or what repository managers think
about preservation.
The purpose of the survey is to inform investigations of preservation
services models identified by the Preserv project (Hitchcock et al. 2007a). In these models
repositories might typically outsource preservation to specialist
service providers, which seems a natural approach since preservation
expertise has always been concentrated in certain types of agency,
notably
national libraries and archives. In Preserv we have been working with
the British Library and the National Archives in the UK. If these
service providers are to produce marketable services they need to know
and understand the need for the services, and the state of the
repositories they are likely to confront.
The basis for the questionnaire was an analysis of the PREMIS set of
preservation metadata mapped to the Preserv models of preservation
services (Hitchcock et al.
2007b). The analysis aimed to
identify those elements of the PREMIS set that could be accommodated in
the model, and then tried to place responsibility for generating those
metadata among the different players in the model, which included
authors depositing in a repository, the repository software, the
repository administrators and preservation services. By picking out
some elements that clearly, or potentially, fall within the domain of
the repository and framing the questions around those elements, we can
begin to discover how prepared repositories are for preservation.
The results were revealing and, in some cases, surprising and
concerning:
- No repositories surveyed had a formal preservation policy
- Preservation policy is being preceded by de facto policies on file
formats and transformations without provision for acquiring source
versions
The first finding is not surprising as it
mirrors the Cornell Survey of Institutional Readiness: "Too often, an organization undertakes
responsibility for digital stewardship without first ensuring that the
necessary policies and controls are in place or that the institution
itself views digital preservation as a core mandate." (Kenney
and Buckley 2005)
The lack of preservation policy can be rectified by good
repository policy (not just preservation policy, which will emerge from
general considerations). Producing good preservation policy could be
assisted by practical advice from prospective service providers. The
problem is that the services available to repositories
currently are mostly experimental, and most of the emphasis has been on
repository DIY
preservation. As we will see, repositories are developing strongly and
are capable in many areas of repository administration, but
unsurprisingly have less expertise for
serious preservation.
In the context of the survey the second
finding ought to be surprising - although less so to those who view
repository content regularly - since the general tone of the responses
is that
managers are open to advice, and prepared to wait for examples of good
practice to emerge. Restricting file
formats that can be deposited runs counter to this approach and
unwittingly introduces an additional risk factor, because it
leads to original source data being transformed without documentation
prior to deposit. In other words, documents and information both useful
and necessary to the ongoing process of preservation are being
lost. An example is the demand for papers to be deposited in PDF
format. Typically the PDF version is produced by saving from a word
processing application such as MS Word, so the Word version may be
lost. It is inevitable that versions will be lost unless
restrictions on presentation formats are accompanied by a demand for
the source version to be deposited.
Survey method and participants
This was a closed survey carried out in June 2006 by email rather than
by an open Web form, and was targetted at selected repository managers.
Repositories were selected from the Registry of Open Access
Repositories (ROAR) using two criteria:
- The largest repositories by volume of content, i.e. those with
most content to preserve (obtained by using the ROAR 'Sort by Total OAI
Records' filter button)
- From 1, those with a 'Preserv profile' (may need to scroll and
page the list to find an example)
Preserv profiles were produced by applying the PRONOM-DROID
file format identification service from The National Archives (Brown
2005) to repository data from the Celestial OAI data harvester and
presenting the resulting graphical view of a repository broken down by
file formats
through the ROAR user interface. For more on PRONOM-ROAR
profiling see this short illustrated guide http://trac.eprints.org/projects/iar/wiki/Profile.
Since a
knowledge of the file formats of objects in a repository is a
prerequisite for preservation planning, the availability of a Preserv
profile provided a reference point for repositories included in the
survey. It also offered the chance to ask repository managers to check
the
profiles and, since Preserv profiles were new at that time and were
being revealed to managers for the first time, perhaps acted as an
incentive to participate.
Size and classification of response
As a result of these considerations candidate repositories were
identified and contacted, with 21 repositories
completing
the questionnaire.
Preserv profiles were available for repositories based on only two
types
of software, EPrints and DSpace (for reasons explained in the
PRONOM-ROAR
profiling guide), so the survey
was by definition
restricted to these types of repositories. The aim was to achieve a
roughly equal balance between the two types in the initial invitations,
but the random nature of the responses led to an eventual imbalance,
with 15 EPrints and 5 DSpace repositories contributing (and one
institution running both). The aim was not to investigate differences
between repositories, but this detail is given as a possible
contributory factor in some results.
Another difference is between institutional and subject repositories.
The primary target of the survey was IRs, but four subject repositories
also responded. Among the IRs, three were specialised towards a
particular type of content such as dissertations, and one repository
was based in a single school rather than serving the whole
institution.
How content is deposited in repositories
Before asking about content in the repositories, we need to know how it
arrives there because this determines how much information, or
metadata, about the content can be
acquired at the point of deposit or ingest, and how reliable that
information might be. The original target for IRs was open access
content, copies of published research papers self-archived by their
authors, a low-cost way of building content. Alternatively deposit
might be mediated by someone other than the author. For example, some
senior or prolific authors might delegate deposit to secretaries or
PAs. Where legacy papers are being added to a repository on a large
scale departments might organise batch deposit from existing databases.
Or for repositories where it proved hard to generate content through
self-archiving, deposit might be mediated by repository staff or
designated editors to reduce the time required by authors. Each of
these processes has an effect
on the deposit process, notably on the quality of metadata, with
repository-mediated deposit potentially offering the highest quality
metadata, but with
higher costs for the repository.
In the questionnaire respondents were asked to estimate the use of each
type of deposit.
1 How is new material deposited in
your
repository: by author self-archiving; mediated deposit by an agent on
behalf of the author (e.g. a personal assistant); mediated deposit by
repository staff? If more than one method is used, can you indicate
rough proportions, or which method predominates?
Some responses gave percentage estimates, while others indicated the
predominant method, so the results are presented in two ways in Table 1.
Table 1: Method of deposit in
repositories ranked by content volume (based on estimates from
repository managers)
Type of deposit
|
Dominant method
|
By percentage (all repositories
types*) |
By percentage (subject
repositories) |
| Repository-mediated |
8 repositories |
50%
|
38%
|
| Self-archiving |
5
|
35%
|
43%
|
| Author-agent-mediated |
2
|
17%
|
19%
|
| Inconclusive |
5
|
|
|
* 15 repositories provided figures that were used in calculating
this result
In percentage terms we find the same order and similar proportions
among all surveyed repositories as for the dominant method, but greater
use of self-archiving for
the four subject repositories.
One repository did not give a usable indication for this table, but
summed up the range of options available to repositories: "We are
shifting towards more
self-deposit: 4 schools are fully self-deposit; 3 use nominated
depositors; the rest export data from school databases. Repository
staff will not deposit but will do QA."
Repository preservation policy
The strategy for preservation should be determined by the nature and
need of the repository, and should be driven by repository policy
rather than the other way around. Hence
one of the first things the
survey sought to discover was to what extent policy precedes
preservation actions; indeed, if there is any policy. Our expectation
was that, given the current focus on growing content,
quite reasonably many IRs would not yet have a formal preservation
policy. In a survey of
'institutional readiness' for digital preservation, Kenney and Buckley
(2005)
found that:
"Developing
policies is a good first step,
but they must be vetted and approved at the senior management level,
and then implemented for a digital preservation program to develop
effectively. ... only about one third of the
surveyed institutions have completed all three steps."
2 Does the repository have any
existing
policy on preservation? Can you point us to the relevant passage?
Yes 1 No 18
This result does not even reach the level found in the Cornell survey.
Policies were variously described as 'in development', and 'unwritten
policies', but strictly none is likely to be sufficient in
current form to
guide all preservation decisions. Yet this is a reasonable
and flexible position at this stage in the development of repositories,
particularly if long-term preservation policy is to be founded on
established practices and wider policies of repositories.
Here are two example repository
policies, not preservation policies, although they may provide a basis
on which to build preservation policy. Neither repository citing these
examples answered 'yes' to this question:
OpenDOAR has produced a useful and practical repository policies tool (http://opendoar.org/tools/en/policies.php)
that helps build preservation policy on top of policies for metadata,
data, content and submission. Its preservation policy definition form
is especially perceptive for including provision for the repository to
work with external partners, such as preservation service providers.
Putting preservation into practice
Preservation actions can take many forms. Even personal computers are
backed up, which can be considered a simple form of preservation. So we
asked repository managers if any actions that might be considered
preservation were performed on their repositories, based on examples
from byte preservation (storing the bits) through
processes of
increasing complexity and specialisation such as emulation.
3 Does the repository implement any
preservation measures, either
internally or with external agents/services? If so, do any of those
measures include the following example preservation services:
- Byte preservation;
- Transformation (migration on ingest
by the service provider);
- Rendering;
- Emulation
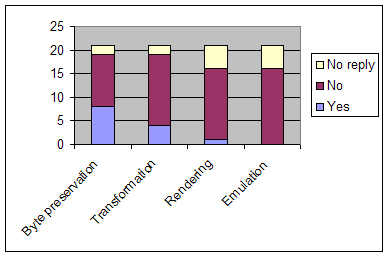
Figure
1. Preservation measures adopted by repositories
These preservation measures increase in complexity from right to left
in Figure 1. There is a clear trend that shows some examples of
the simplest activity (byte preservation), but with fewer or no
examples of the more
specialised activities. While we would expect the latter to be
performed by specialist service providers rather than individual
repositories, the question left open the possibility for services to be
performed by agents, and in this respect the following partnerships
were mentioned - Sherpa-DP, MetaArchive NDIIPP, dissertation copies at
German National Library - so repositories are becoming aware of the
wider possibilities in terms of services, and some embryonic services
appear to be emerging. Other preservation activities cited included
backup, mirroring,
and geographic cluster backup.
It is worth remarking that selection of these example preservation
activities was informed by discussions with the British Library. In
Preserv the British
Library is an exemplar service provider. From an OAIS perspective,
while the first two activities focus on data ingest, the
latter two services are concerned with dissemination and presentation.
What is striking
is that each of these services is different to the extent it changes
the relationship between the service provider and the repository.
Preservation
need not be a monolithic service. By choosing services based on a
developed institutional profile this potentially changes the
relationship
from a simple 'you give us the data and we store it' to a more tailored
and interactive partnership.
Remember that although repositories are admitting to relatively
simple
preservation actions, these are being performed in the absence of any
guiding policy. Later in the report (Q5c) we will find the incidence of
transformation may be greater than revealed here.
Selection for preservation
One of the largest problems facing any preservation example is
selection of content to be preserved. With potentially high growth,
diversified sources such as repositories, any
over-specified selection approach could waste time and resources
before becoming dated and requiring review. Next the survey tried to
find out about selection criteria used by the repositories.
4 What part of its contents does the
repository designate for
preservation? All; if not all, what are the selection criteria?
All 11 No answer 8 Other 2 ('undecided', 'don't
designate
(currently)')
This is probably a positive answer, showing that repositories have so
far resisted the temptation to over-specify selection, while planning
for the bold but practical step of preserving all content. This is
certainly feasible while the simplest forms of preservation are being
applied, but some form of selection may be necessary depending on
object types and formats for more complex preservation requirements.
This analysis might be carried out in conjunction with a service
provider, and begins to show the value of the Preserv profile.
File formats: the crux of preservation
We are now reaching the specifics of preservation practice, which
centre on file formats, special features within formats, delivery
formats, the recording of provenance, user authentication, rights and
identifiers. These are the kind of issues that populate PREMIS, and the
following questions are informed by its metadata set.
5a Does the repository have a policy
on submission file formats?
Y 13 N 4 No reply 4
Comments
- Prefer PDF / DOC / PPT / HTML
- Recommend using PDF or HTML
- Require submission in PDF or HTML
- PDF (Sherpa policy)
- Accept all formats, text documents should be at least be PDF,
preferred PDF/A
- Use DSpace supported, known, and unknown formats (3 respondents)
- Rendering software must be free, i.e. Acrobat, text, PostScript,
HTML
An example de facto format
'policy' is:
It is not presented as a policy, but in this guide to submission the
step-by-step approach begins with 'Start by converting your project
report to PDF-format' and points to a tabbed section on converting to
PDF, which in turn emphasises the point with 'the project report should
always be submitted as an Adobe PDF file'.
Note that where there is no preservation policy (Q2), we now have
'policies'
on formats. The disconnect with general repository and preservation
policy potentially has major implications for preservation. This is
presumably only temporary: building general policy is hard, while
favouring selected formats is easy. Where the disconnect persists
repositories
could be creating preservation problems for the future. A better
temporary approach might be no policy: no format policy. An
all-embracing repository policy is best.
5b Are there any restrictions for
submitting authors?
Y 7 N 11 unclear 3
- Word, PDF, Postscript, ASCII, HTML, LaTex, PowerPoint (for
conference posters), JPEG (images of book jackets).
- PDF required, other formats optional
- PDF only
- Accept HTML, ASCII, PDF
- Ask authors to submit PDF
- Majority of deposits PDF; allow other formats, e.g. HTML, RTF
This result tends to confirm that of 4a, again with an emphasis on the
requirement for PDF.
Interestingly, fewer repositories claim to impose restrictions on
formats than have format policies, suggesting the policies are not
rigidly prescriptive.
5c Does the repository
transform submitted formats in any way?
Y 15 N 2 no reply 4
- Convert Word docs to PDF
- Most files (e.g. Word, Postscript, PowerPoint) converted to PDF
- Transform source files to PDF
- Proprietary formats usually converted to PDF
- Transform textual documents to PDF/A
- Maths Latex, PS to PDF
- Author option to convert to supported format
- Video or graphic files zipped
It follows that if repositories have strong preferences for particular
deposit formats but do not rigidly enforce this, the findings of 5a and
b, then they are likely to attempt to produce those formats by
transforming non-conforming documents. This is borne out here. This is
not a bad approach, so long as it is accompanied by careful retention
of the source, i.e. the original document that is transformed, and by
documenting the transformation (ideally using PREMIS guidelines). We
cannot tell if that happens in these cases, although the next question
offers some clues.
5d Does the repository require the
original source version from the author?
Y 1 N 13 no reply 7
- Source file formats (e.g. Word, TeX, WordPerfect) can be deposited
- Keep the original sources if deposited
- Authors asked to deposit a copy of "own final corrected draft
version" rather than "publisher's formatted version"
- Encourage and accept, stored in a "dark" archive
This is the most alarming result from this set. It is inconsistent to
have format 'policies' without a commitment to obtaining the source
copy.
The inevitable consequence of requesting non-authored formats such as
PDF without a requirement for source is that authors, or someone else,
will produce the transformation, leaving the repository short of those
features just identified above, source and documentation. There is some
consolation in the result of 4c, which indicates that source is often
received even if not required, but it would be simple to make source a
requirement, and is an essential supplement to any format policy.
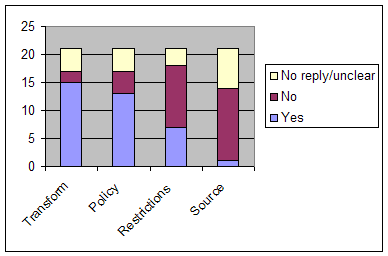
Figure
2. How repositories manage file formats (ordered by most active)
Re-ordering the responses to questions 5a-d by the most active
approaches (Figure 2) gives a clearer picture of priorities, from the
preference for a simple and uniform range of formats achieved through
transformation into selected formats, in some cases for reasons stated
in simple policy. The level of adoption of transformation means that
authors face fewer restrictions on deposit than may have been the case.
All of this is done effectively without the requirement for source
copies.
Summing up Q5, clearly formats are not just the crux of preservation
but of policy
too. Repositories may not have preservation policies, but some have
policies on the formats that can be deposited. This mainly centres
around the demand for PDF. This is not the place to debate the merits
of particular formats, except to say that contrary to received wisdom,
the case for PDF as a preservation format is not clear cut. Apart from
the special case of PDF/A (archival) version it was not designed
specifically for
preservation, though it has many useful features for
repository use.
Managers most probably believe that presentationally PDF offers more
consistency,
stability and openness than other formats, but it is not an originating
format and therefore where all but one format 'policies' fall down is
that they do not
supplement the policy with a demand for the original source version.
This is a critical omission that undoes any good intent that may lie
behind a format policy.
Limitations on admissible formats may be a
natural if naive approach, which can ultimately be improved with better
preservation planning and format risk assessment (Arms and Fleischhauer
2005, Brown 2003, FCLA 2005), and the
advent of better services and tools, e.g. PRONOM-DROID (http://www.nationalarchives.gov.uk/aboutapps/pronom/tools.htm),
also GDFR (Global Digital Format Registry http://hul.harvard.edu/gdfr/)
and JHOVE (JSTOR/Harvard Object Validation Environment http://hul.harvard.edu/jhove/).
Special format features
A common complicating factor for preservation is the inclusion of
special features within formats, such as links or scripting. If
repositories allow such features, how would they become aware of the
presence of such features on deposit? Unlike with primary file formats,
which can be identified on ingest by services such as PRONOM-DROID,
there is
no automated test for these features.
6 Is the repository aware of special
features within format types, e.g.
links within pdf, Javascript within html? If so, how is it aware of
these, what features does it look out for, and are there any
restrictions?
Y 3 N 16 no reply 2
Clearly most repositories do not know about the inclusion of special
format features. We cannot estimate the scale of usage of such features
in repository content, even in Preserv profiles. Usage could be low,
although the types of features referred to in PREMIS and highlighted in
the question are not that uncommon. Those repositories that are aware
of these features become so because authors are asked to note them.
For IRs this is an area that requires more investigation and ultimately
probably requires the intervention of specialist services to identify
the scale of the problem and to advise on best practice.
Delivery packages
When digital data is deposited, stored or moved around - three
essential activities for preservation - as with physical materials it
helps if they are packaged in some way. This might be to save storage
space or bandwidth on transfer (compression), to collect the components
of a presentation such as text and images (zipped), or to secure the
data (encryption).
7 Does the repository allow
submission of files in the following forms:
compressed, encrypted, zipped?
Y 9 N 7 mixed response 4 no reply 1
The mixed responses were revealing, showing that invariably compression
and zipping were acceptable but encryption is not permitted. Among
those that answered 'yes' to all three, one noted that encryption is
'not recommended'. Another accepts these forms in the confident
knowledge they are not used, but does not indicate whether this
position
would remain were they to be used.
As with most of the technical features highlighted in the survey, use
of these packaging methods is not driven by preservation but has
implications for preservation. Unlike the special features of Q6, these
forms are readily identifiable, and repositories can decide what to do
on ingest in the cases of compression and zipped files. Encryption is
more complex and is probably best avoided by repositories in the
general case, especially by those that primarily provide access to
content, although it may be necessary to consider examples
case-by-case, perhaps with specialist advice on preservation.
Tracking change
It is the nature of digital documents that they change over time, in
content and in format. They may be changed by author or other agent.
Sometimes it is the act of change that requires preservation action; on
other occasions it may be the act of preservation itself (such as
format migration) that causes a
change. Then there are new digital objects that derive from some
processing or
combination of other objects. Tracking these changes might generally be
referred to as digital provenance.
In the context of PREMIS the importance of digital provenance is to
track 'derivation relationships' at the file and representation level,
and PREMIS requires that relationships between agents and events, and
between objects and events, are documented.
It is immediately apparent that these issues are becoming more
difficult to define and understand among non-specialists, even before
considering how it might be done. This needs to be borne in mind for
the next question, about provenance.
8 Does the repository have a
process to record and track provenance of
submitted materials?
Y 6 N 11 qualified response 3 no reply
1
The bald figures disguise a complexity and confusion about provenance
that needs more investigation but which is hinted at in the
accompanying comments. Among the repositories that claimed to track
provenance, one says it is a 'feature of the repository software'
(DSpace software in this case), others say that provenance is 'not
necessarily handled by software' or it is 'not preservation
provenance', while another admits its provenance tracking is 'off-line
and not robust'.
Among those not tracking provenance one notes that the 'submitting
author is always linked to documents', while another repository intends
to 'use LDAP and JHOVE'.
Some repositories are neither tracking provenance nor not, but
have some processes that may play a role in fuller, more formal
provenance tracking, e.g. tracking depositors (by changing the file
naming convention if the author is not the depositor; another
tracks 'who submits what'). Another valid contributory factor in
provenance for the type of materials that would be expected in IRs,
postprints of peer reviewed published
papers, is to perform 'Metadata checks for published works'.
Clearly, a wide range of interpretations of what provenance is. This
looks like another good reason to outsource repository preservation to
specialist service providers, recognising that repositories have to put
in place mechanisms for acquiring sufficient data from the point of
ingest to serve the needs of provenance tracking by the service
provider. As an example, it is worth noting again that acquiring, say,
a
PDF from an author without the source version means there is likely to
be a gap in the provenance information for that object from the outset..
Depositors: who do you trust?
Even though we learned in this survey that there may be less
self-archiving deposit in IRs than might have been anticipated (Q1), it
is still in the nature of IRs that they will have many depositors, and
repository software is designed to facilitate this. With so many
depositors, however, how can the repository be sure they are legitimate
depositors, and that what they are depositing is what is purported?
There are different levels to this question, e.g. security, and another
which concerns preservation. In the latter case the concern might be to
verify that the depositors are who they say they are and what they are
depositing is what they say they are depositing. This is the process of
authenticating users and files.
9 Does the repository authenticate
users or files at submission? If so,
how is this done?
Y (Users) 13 Y (files) 0 Y (both) 2 N 4 No answer 2
It is not unexpected that the majority of repositories have some kind
of log-in process for depositors, often tied to an LDAP directory or
other maintained directory of people in the institution, and this can
be considered a viable form of authentication of users. Repository
software supports this. It is less obvious how to authenticate files.
File format checking on ingest may cover one aspect, and some editorial
checking could help. First, however, repositories must identify the
concerns that file authentication might help resolve before prescribing
which actions to take.
Who has the rights?
Creators of new works inherently own the rights, including
copyright, to use and disseminate those works. In some cases they may
assign those rights exclusively, to a publisher for example. In other
cases creators might grant non-exclusive rights, as is typically the
case for
repositories. In both cases there is an exchange to enable each party
formally to perform the tasks intended, e.g. to publish, to provide
access, etc., without recourse to law. With so much information now
being disseminated freely on the Internet there is some benefit in
making the
rights of users more explicit, leading to initiatives such as Creative
Commons.
For repositories there is an additional complication. Authors of
self-archived or deposited papers that are intended to be formally
published in peer reviewed sources have to be careful they do not
compromise their ability to publish and to assign some rights to the
publisher. Yet, since repositories are formal, long-term resources they
too need to obtain sufficient rights from the author, or publisher in
the
case of exclusive rights, to continue to perform the required tasks
over time without contest. Without being concerned here about the
rights and wrongs of author agreements with publishers, the survey
sought to discover whether repositories were seeking any rights (Q10a)
and
whether those rights might cover anticipated preservation scenarios
(Q10b).
10a Does the repository have any
explicit agreement with authors on rights? If yes, where is this
expressed (URL?)
Y 17 N 3 qualified 1
Almost all repositories surveyed present some sort of
agreement to authors during the deposit process. This can be built into
repository software. One repository noted that it uses the DSpace
license with minor changes. Whether they are using agreements that are
correct and adequate is another matter, and requires examination of
individual agreements, but in principle repositories are taking the
correct actions in seeking agreements. From the responses to the
question some example repository-author agreements are highlighted
below.
As can be seen by examining these agreements, we can anticipate a range
of impacts on preservation activities. It could be argued the Caltech
agreement has
sufficient provision to cover preservation, although it doesn't refer
to preservation explicitly. Roskilde obtains permission
'to archive', although whether this would be adequate to cover all
preservation actions described by PREMIS and referred to here, other
than simple byte storage, is debatable. SLU nowhere uses language that
be be construed as pertaining to preservation.
If a repository has sufficient rights to copy, store and present
content, it would appear
that it naturally has the rights for some form of preservation. That
would be to
assume at best a limited range of preservation actions, however, and
also that
the repository performed the task of preservation
itself. In the case of preservation service providers this introduces
another agent, and the rights vested with the repository do not
necessarily transfer to that agent, especially where other rights
holders may be involved. Thus we need to find out whether any
repository
agreements cover preservation specifically and adequately for the for
the services envisaged.
10b If yes, does it refer to
rights for
preservation?
Y 4 N 12 no answer 5
On this score the first result (Q10a) is effectively reversed. If in
some senses the preservation service provider model seems a natural
approach for repositories, this result suggests that few repositories
are aware of the model. For the types of service providers envisaged,
national libraries and archives, the inclusion of preservation rights
in repository author agreements will be a prerequisite to services.
This ought not to be a major obstacle in principle, perhaps beginning
with the following examples:
ANU refers to
preservation explicitly, although non-specifically, so its overall
effectiveness for preservation services is hard to guage. In contrast,
the University of Dortmund's agreement with authors is the
clearest example of covering preservation in its fullest sense,
including agreement to transformation and migration to other electronic
and physical formats, as well as transfer to the German National
Library (Wollschlaeger 2006) granting the library the same rights as
the
Dortmund repository.
Somewhat surprisingly, DSpace repositories in the survey do not appear
to have adopted the DSpace at MIT licence that extends clauses to
cover possible preservation actions within the IR (illustrated by
MacColl 2004):
"You agree that MIT may, without
changing the content, translate the
submission to any medium or format for the purpose of preservation. You
also agree that MIT may keep more than one copy of this submission for
purposes of security, back-up and preservation."
The
longer-term issue will be to identify what rights service providers
need, which in turn will depend on the types of services offered,
including access perhaps. The
original PREMIS standard considered only rights required for
preservation activities. Coyle (2006) investigated how this might be
expanded, including rights for access, which might become relevant for
the service provider model. For
now, however, most preservation services are still at the early stage
of
experimentation and evolution.
A question of identity
All repositories and preservation activity would flounder unless items
were clearly and distinctively identified. Both EPrints and DSpace
software automatically assign identifiers to deposited items: DSpace
uses the Handle system, which also underpins the DOI system, while
EPrints generates its own ID numbers. These are perfectly adequate and
persistent within the repository systems that generate them. They may
be criticised for lacking an external agency to regulate and reference
the IDs, such as in the DOI example. In the case of preservation
services, where content is accessed and acted upon by an external
system, this raises the question of whether the EPrints and DSpace ID
systems are adequate and useful for this purpose, i.e. whether the IDs
will migrate effectively, or whether service providers will map to new
IDs.
At this stage these issues are moot, however. What we want to know now
is simply whether and how repositories generate any IDs.
11 Does the repository use IDs
generated by the repository software, or
does it have its own system of IDs?
Repository generated 18 Manually
generated 2 no answer 1
Confirms what was expected and what preservation services prospectively
need to work with. Few repositories have need of more sophisticated
systems of IDs at this stage, but may need to consider how that might
change when repositories interact with more Web services, including
preservation services.
Conclusion
Preservation begins with policy. For IRs this need not start with
preservation policy, which can be hard and sometimes technical. More
general repository policy considerations, starting with OpenDOAR's
policy tool, for example, or open access mandates, will lead naturally
towards preservation considerations and can inform a repository's need
for preservation. That's the good news. The bad news is that some
repositories may be inadvertently turning that order around, and making
decisions based on technical preservation considerations, in the form
of restricting file formats. As well as being a limited preservation
strategy, that approach risks compromising general repository policy
and content, and may affect the ability of a repository to adopt other
policies and attract content in the future. One way repositories can
avoid this temporarily is to couple file format control with a simple
policy requiring deposit of source formats, but this is only a partial
solution that risks turning away content that does not or cannot
conform. The only way to avoid that is to make a full assessment of the
institutional needs and purposes the repository is intended to serve,
which brings us back full circle to general considerations.
The results of this survey present an impression of how repositories
are approaching the issue of preserving their contents. Given the scale
and
quality of the data the results do not constitute market trends. The
aim is to
inform the investigation of preservation services for repositories,
which we believe will be provided by specialist service providers.
Those providers need to know the scale and shape of the task facing
them, and
this survey will enable them to understand repositories and to
construct appropriate services. Even if the results prove to be
atypical of repositories generally - although bear in mind that in
terms of content the
repositories selected are among the largest IRs
- the aim is to identify and advise on the best and worst aspects of
the practices found, in particular short-term and ad hoc policies founded on file
formats alone, and inconsistencies in policy development.
References
Arms, Caroline R. and Carl Fleischhauer (2005) Digital Formats: Factors
for Sustainability, Functionality, and Quality, Second
IS&T Archiving Conference, Washington, D.C., April 2005
http://memory.loc.gov/ammem/techdocs/digform/Formats_IST05_paper.pdf
see also the authors' ongoing resource Sustainability of Digital
Formats Planning for Library of Congress Collections
http://www.digitalpreservation.gov/formats/index.shtml
Brown, Adrian (2005) Automatic Format Identification Using PRONOM
and
DROID,
The National Archives,
Digital Preservation Technical Paper: 1, 17 September 2005
http://www.nationalarchives.gov.uk/aboutapps/fileformat/pdf/automatic_format_identification.pdf
Brown, Adrian (2003) Selecting File Formats for Long-Term Preservation,
The
National Archives, Digital Preservation Guidance Note: 1, 19 June 2003 http://www.nationalarchives.gov.uk/documents/selecting_file_formats.pdf
Coyle, Karen (2006) Rights in the PREMIS Data Model, Report for the
Library of Congress, December 2006 http://www.loc.gov/standards/premis/Rights-in-the-PREMIS-Data-Model.pdf
FCLA (2005) Recommended Data Formats for Preservation Purposes in the
FCLA Digital Archive, Florida Center for Library Automation, June 2005 http://www.fcla.edu/digitalArchive/pdfs/recFormats.pdf
Hitchcock, Steve, Tim
Brody, Jessie M.N. Hey and Leslie Carr (2007a) Digital Preservation
Service Provider Models for Institutional Repositories: towards
distributed services, Preserv project, January 2007 http://preserv.eprints.org/papers/models/models-paper.html
Hitchcock, Steve, Tim
Brody, Jessie M.N. Hey and Leslie Carr (2007b) Preservation Metadata
for Institutional Repositories: applying PREMIS, Preserv project,
January 2007 http://preserv.eprints.org/papers/presmeta/presmeta-paper.html
Kenney, Anne R., et al.
(2003) Digital
Preservation Management: Implementing Short-Term Strategies
for Long-Term Problems, Cornell University, September 2003 http://www.library.cornell.edu/iris/tutorial/dpm/eng_index.html
Kenney, Anne R. and Ellie Buckley (2005) Developing Digital
Preservation
Programs: the Cornell Survey of Institutional Readiness, 2003-2005, RLG
DigiNews, Vol. 9, No. 4, August http://www.rlg.org/en/page.php?Page_ID=20744
Lynch, Clifford A. (2003) Institutional Repositories: Essential
Infrastructure for Scholarship in the Digital Age. ARL Bimonthly Report, no. 226,
February, 1-7 http://www.arl.org/resources/pubs/br/br226/br226ir.shtml
MacColl, John (2004) DSpace Institutional Repositories
and Digital Preservation, DPC Forum
on Digital Preservation in
Institutional Repositories, London, 19th October, slide 5 http://www.dpconline.org/docs/events/041019maccoll.pdf
PREMIS (PREservation Metadata: Implementation Strategies)
Working
Group (2005) Data Dictionary for
Preservation Metadata: Final Report of the
PREMIS Working Group, May 2005
http://www.oclc.org/research/projects/pmwg/
Wollschlaeger,
Thomas, ETD's
as pilot materials for long-term preservation efforts in kopal (pdf
8pp), 9th International Symposium on
Electronic Theses and Dissertations,
Quebec City, June 7 - 10, 2006
http://www6.bibl.ulaval.ca:8080/etd2006/pages/papers/SP10_Thomas_Wollschlaeger.pdf
Appendix
We are grateful to the managers of the following repositories who
participated in the
survey and agreed to be acknowledged in this report:
Queensland University of Technology, OpenMED@NIC (India), Organic
eprints (Denmark), University of Queensland, University of Dortmund,
SLU (Swedish University of Agricultural Sciences), Georgia Tech,
Roskilde University, Australian National University, Universidade do
Minho, LMU Munich University
(dissertations), dLIST Digital Library of Information Science and
Technology, White Rose Consortium
of the Universities of Leeds, Sheffield and York, Università di
Bologna (AMS Acta), University
College London, Glasgow University, Southampton University, School of
Electronics and
Computer Science (Southampton University), Oxford University, E-LIS
Eprints for Library and Information Science,
Caltech (Authors)